Imagine having a powerful tool that measures your software team’s efficiency, identifies areas for improvement, and unlocks the secrets to achieving speed and stability in software development – that tool is DORA metrics. DORA originated as a research team within Google Cloud, which played a pivotal role in developing these four key metrics to assess and improve DevOps performance. However, organizations may encounter cultural resistance when implementing DORA metrics, as engineers might fear evaluations based on individual performance. To mitigate this resistance, organizations should involve team members in goal setting and collaboratively analyze results. It is also important to note that DORA metrics are designed to assess team efficiency rather than individual engineer performance, ensuring a focus on collective improvement.
DORA metrics offer valuable insights into the effectiveness and productivity of your team. By implementing these metrics, you can enhance your dev practices and improve outcomes. DORA metrics also provide a business perspective by connecting software delivery processes to organizational outcomes, helping you understand the broader impact on your business. Fundamentally, DORA metrics change how teams collaborate by creating shared visibility into the software delivery process. They enhance collaboration across development, QA, and operations teams by fostering a sense of shared ownership and accountability. The DevOps team plays a crucial role in managing system performance and deployment processes, ensuring smooth and efficient software delivery.
In this blog, we will delve into the importance of DORA metrics for your team and explore how they can positively impact your software team’s processes. DORA metrics are used to measure and improve delivery performance, ensuring your team can optimize both speed and stability. Many teams, however, struggle with the complexity of data collection, as DORA metrics require information from multiple systems that operate independently. To effectively collect data, teams must gather information from various tools and systems across the Software Development Lifecycle (SDLC), which can present challenges related to integration, access, and data aggregation. Legacy systems or limited tooling can make it difficult to gather the necessary data automatically, leading to time-consuming manual processes. To improve DORA metrics, teams should focus on practices like automation, code reviews, and breaking down work into smaller increments, which can streamline data collection and enhance overall performance.
To achieve continuous improvement, it is important to regularly review DORA metrics and compare them to industry benchmarks. Regularly reviewing these metrics helps identify trends and opportunities for improvement in software delivery performance. Join us as we navigate the significance of these metrics and uncover their potential to drive success in your team’s endeavors. DORA metrics help teams measure their performance against industry benchmarks to identify competitive advantages. By tracking DORA metrics, teams can set realistic goals and make informed decisions about their development processes. Benchmarking the cadence of code releases between groups and projects is the first step to improve deployment frequency, lead time, and change failure rate. DORA metrics also help benchmark and assess the DevOps team's performance, providing insights into areas that need attention and improvement.
DevOps Research and Assessment (DORA) metrics are a compass for engineering teams striving to optimize their development and operations processes.
In 2015, The DORA team was founded by Gene Kim, Jez Humble, and Dr. Nicole Forsgren to evaluate and improve software development practices. The aim is to enhance the understanding of how development teams can deliver software faster, more reliably, and of higher quality. DORA metrics provide a framework for measuring both the speed and stability of software delivery. These metrics can be classified into performance categories ranging from low to elite based on team performance. High performing teams typically deploy code continuously or multiple times per day, reflecting a high deployment frequency. DORA metrics are four key measurements developed by Google’s Research and Assessment team that help evaluate software delivery performance.
Software teams use DORA DevOps metrics in an organization to help improve their efficiency and, as a result, enhance the effectiveness of company deliverables. It is the industry standard for evaluating dev teams and allows them to scale. DORA metrics measure DevOps team’s performance by evaluating two critical aspects: delivery velocity and release stability. DORA metrics can also be used to track and compare performance across multiple teams within an organization, enabling better cross-team collaboration and comprehensive analysis.
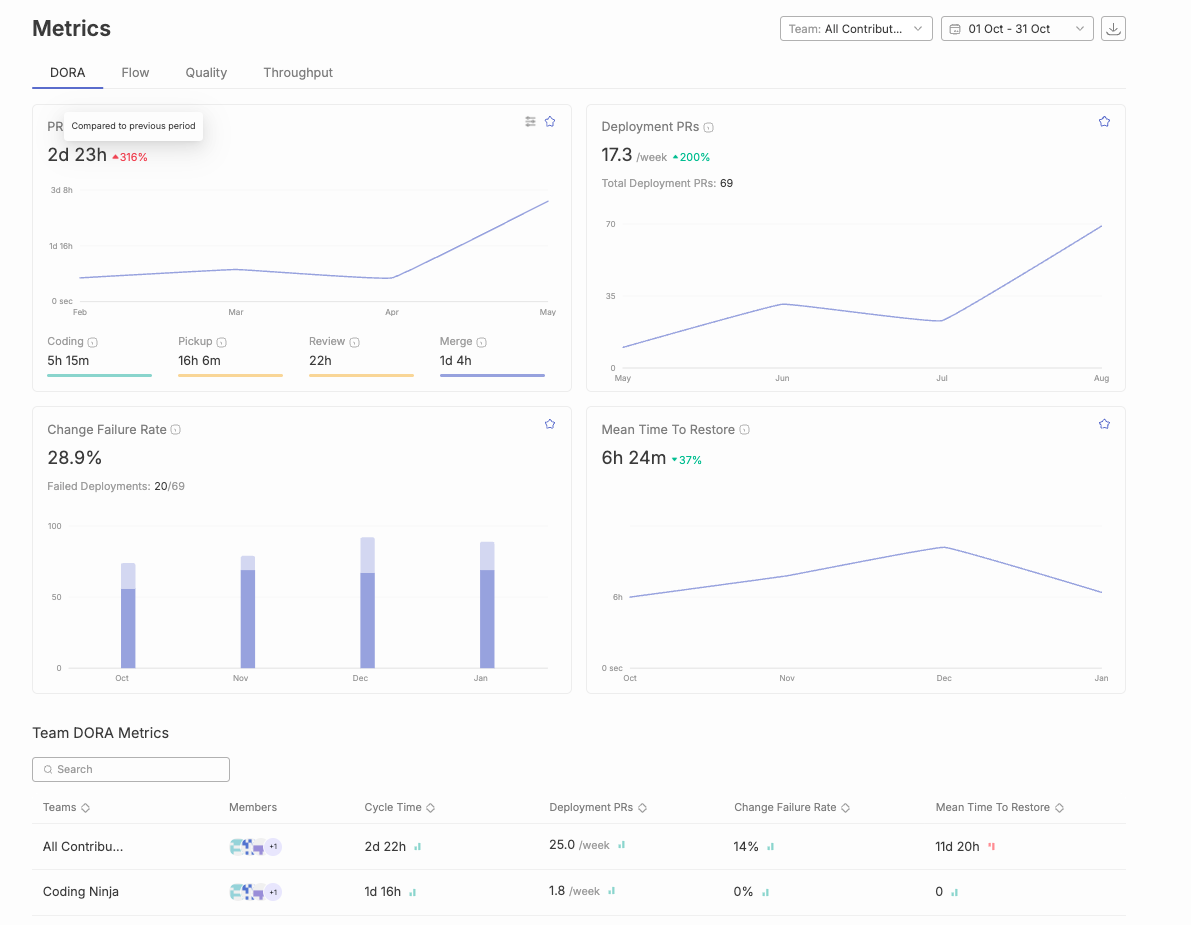
The key DORA metrics include deployment frequency, lead time for changes, mean time to recovery, and change failure rate. These are also referred to as the four DORA metrics, four key measurements, or four metrics, and are essential for assessing DevOps performance. They have been identified after six years of research and surveys by the DORA team. Without standardized definitions for what constitutes a deployment or a failure, comparisons can be misleading and meaningless across teams and systems, making it crucial to establish clear criteria for these metrics.
To achieve success with DORA metrics, it is crucial to understand them and learn the importance of each metric. Here are the four key DORA metrics: Implementing DORA metrics requires collecting data from multiple sources and tracking these metrics over time. To implement DORA metrics as part of DevOps practices, organizations should establish clear processes or pipelines, integrate tools such as Jira, and ensure consistent data collection, analysis, and actionable insights. Effective data collection is vital, as these metrics measure the effectiveness of development and operations teams working together. Reducing manual approval processes can help decrease lead time for changes, further enhancing efficiency.

Implementing DORA Metrics to Improve Dev Performance & Productivity?
Organizations need to prioritize code deployment frequency to achieve success and deliver value to end users. Teams aiming to deploy code frequently should optimize their development pipeline and leverage continuous integration to streamline workflows and increase deployment efficiency. However, it’s worth noting that what constitutes a successful deployment frequency may vary from organization to organization.
Teams that underperform may only deploy monthly or once every few months, whereas high-performing teams deploy more frequently. It’s crucial to continuously develop and improve to ensure faster delivery and consistent feedback. If a team needs to catch up, implementing test automation and automated testing can help increase deployment frequency and ensure successful deployments by maintaining code quality and deployment stability. Tracking deployment events is also essential for understanding deployment frequency and improving release cycles. If a team needs to catch up, implementing more automated processes to test and validate new code can help reduce recovery time from errors.
In a dynamic market, agility is paramount. Deployment Frequency measures how frequently code is deployed. Infrequent deployments can cause you to lag behind competitors. Increasing Deployment Frequency facilitates more frequent rollouts, hence, meeting customer demands effectively.
This metric measures the time it takes to implement changes and deploy them to production directly impacts their experience, and this is the lead time for changes. Monitoring lead time for changes is essential for optimizing the software delivery process and overall delivery process. Flow metrics can help identify bottlenecks in the development pipeline, enabling teams to improve efficiency. Value stream management also plays a key role in reducing lead time and aligning development efforts with business goals.
If we notice longer lead times, which can take weeks, it may indicate that you need to improve the development or deployment pipeline. However, if you can achieve lead times of around 15 minutes, you can be sure of an efficient process. It’s essential to monitor delivery cycles closely and continuously work towards streamlining the process to deliver the best experience for customers.
Picture your software development team tasked with a critical security patch. Measuring Lead Time for Changes helps pinpoint the duration from code commit to deployment. If it goes for a long run, bottlenecks in your CI/CD pipeline or testing processes might surface. Streamlining these areas ensures rapid responses to urgent tasks.
The change failure rate measures the code quality released to production during software deployments. Adopting effective DevOps practices, such as automated testing and continuous integration, can help reduce change failure rate by catching issues early and ensuring smoother deployments. Achieving a lower failure rate than 0-15% for high-performing DevOps teams is a compelling goal that drives continuous improvement in skills and processes. Change failure rate measures the percentage of deployments that result in failures in production.
Stability is pivotal in software deployment. The change Failure Rate measures the percentage of changes that fail. A high failure rate could signify inadequate testing or insufficient quality control. Enhancing testing protocols, refining code reviews, and ensuring thorough documentation can reduce the failure rate, enhancing overall stability.
Mean Time to Recover (MTTR) measures the time to recover a system or service after an incident or failure in production. MTTR specifically tracks the time to restore service and restore services following an incident in the production environment. It evaluates the efficiency of incident response and recovery processes. Tracking time to restore service is essential for evaluating the effectiveness of operations teams in minimizing downtime. Optimizing MTTR aims to minimize downtime by resolving incidents through production changes. Improvement in deployment frequency and lead time often requires automation of manual processes within the development pipeline.
Downtime can be detrimental, impacting revenue and customer trust. MTTR measures the time taken to recover from a failure. A high MTTR indicates inefficiencies in issue identification and resolution. Investing in automation, refining monitoring systems, and bolstering incident response protocols minimizes downtime, ensuring uninterrupted services.
Teams with rapid deployment frequency and short lead time exhibit agile development practices. These efficient processes lead to quick feature releases and bug fixes, ensuring dynamic software development aligned with market demands and ultimately enhancing customer satisfaction.
Elite performers in DevOps are characterized by consistently high deployment frequency and rapid lead times, setting the standard for excellence.
A short lead time coupled with infrequent deployments signals potential bottlenecks. Identifying these bottlenecks is vital. Streamlining deployment processes in line with development speed is essential for a software development process.
Low comments and minimal deployment failures signify high-quality initial code submissions. This scenario highlights exceptional collaboration and communication within the team, resulting in stable deployments and satisfied end-users.
Teams with numerous comments per PR and a few deployment issues showcase meticulous review processes. Investigating these instances ensures review comments align with deployment stability concerns, ensuring constructive feedback leads to refined code.
Rapid post-review commits and a high deployment frequency reflect agile responsiveness to feedback. This iterative approach, driven by quick feedback incorporation, yields reliable releases, fostering customer trust and satisfaction.
Despite few post-review commits, high deployment frequency signals comprehensive pre-submission feedback integration. Emphasizing thorough code reviews assures stable deployments, showcasing the team's commitment to quality.
Low deployment failures and a short recovery time exemplify quality deployments and efficient incident response. Robust testing and a prepared incident response strategy minimize downtime, ensuring high-quality releases and exceptional user experiences.
A high failure rate alongside swift recovery signifies a team adept at identifying and rectifying deployment issues promptly. Rapid responses minimize impact, allowing quick recovery and valuable learning from failures, strengthening the team's resilience.
In collaborative software development, optimizing code collaboration efficiency is paramount. By analyzing Comments per PR (reflecting review depth) alongside Commits after PR is Raised for Review, teams gain crucial insights into their code review processes.
Thorough reviews with limited code revisions post-feedback indicate a need for iterative development. Encouraging developers to iterate fosters a culture of continuous improvement, driving efficiency and learning. For additional best practices, see common mistakes to avoid during code reviews.
Few comments during reviews paired with significant post-review commits highlight the necessity for robust initial reviews. Proactive engagement during the initial phase reduces revisions later, expediting the development cycle.
The size of pull requests (PRs) profoundly influences deployment timelines. Correlating Large PR Size with Deployment Frequency enables teams to gauge the effect of extensive code changes on release cycles.
Maintaining a high deployment frequency with substantial PRs underscores effective testing and automation. Acknowledge this efficiency while monitoring potential code intricacies, ensuring stability amid complexity.
Infrequent deployments with large PRs might signal challenges in testing or review processes. Dividing large tasks into manageable portions accelerates deployments, addressing potential bottlenecks effectively.
PR size significantly influences code quality and stability. Analyzing Large PR Size alongside Change Failure Rate allows engineering leaders to assess the link between PR complexity and deployment stability.
Frequent deployment failures with extensive PRs indicate the need for rigorous testing and validation. Encourage breaking down large changes into testable units, bolstering stability and confidence in deployments.
A minimal failure rate with substantial PRs signifies robust testing practices. Focus on clear team communication to ensure everyone comprehends the implications of significant code changes, sustaining a stable development environment. Leveraging these correlations empowers engineering teams to make informed, data-driven decisions — a great way to drive business outcomes— optimizing workflows, and boosting overall efficiency. These insights chart a course for continuous improvement, nurturing a culture of collaboration, quality, and agility in software development endeavors.
In the ever-evolving world of software development, harnessing the power of DORA DevOps metrics is a game-changer. By leveraging DORA key metrics, your software teams can achieve remarkable results. These metrics are an effective way to enhance customer satisfaction, mitigate financial risks, meet service-level agreements, and deliver high-quality software. Keeping a team engaged in continuous improvement includes setting ambitious long-term goals while understanding the importance of short-term incremental improvements.
Value stream management and the ability to track DORA metrics are essential for continuous improvement, helping teams optimize delivery processes and benchmark against industry standards. Unlike traditional performance metrics, which focus on specific processes and tasks, DORA metrics provide a broader view of software delivery and end-to-end value. Collecting data from various sources and tools across the software development lifecycle is crucial to ensure accurate measurement and actionable insights. Additionally, considering other DORA metrics beyond the four primary ones offers a more comprehensive assessment of DevOps performance, including deeper insights into system stability, error rates, and recovery times.
Implementing DORA Metrics to Improve Dev Performance & Productivity?



Implement engineering metrics, gather SDLC insights & set continuous improvement goals in your dev teams.
Try Live Demo
We're on a mission to build engaged, productive tech teams. Try it out for free!


Follow us on:




