AI-assisted coding is revolutionizing the software development landscape, and understanding how to use these tools effectively is now essential for engineering leaders, software developers, and technical decision-makers. This comprehensive guide covers actionable best practices, the impact of AI coding tools, and the key metrics for measuring their effectiveness. As AI coding tools become mainstream and critical for engineering excellence, it is vital to understand not only how to leverage them for productivity but also how to maintain code quality, security, and team expertise.
Scope: This article explores AI coding tools best practices, their impact on software engineering, and the essential metrics for tracking their effectiveness.
Target Audience: Engineering leaders, software developers, and technical decision-makers.
Why It Matters: AI coding tools are now mainstream, and their effective use is critical for maintaining engineering excellence and a competitive edge.
Note: AI-assisted coding requires a basic knowledge of software engineering best practices and core AI concepts. Readers should be familiar with foundational development workflows to maximize the benefits of AI tools.
What Are AI Coding Tools?
AI coding tools are software applications that can produce code from natural language descriptions or existing codebases. These tools leverage artificial intelligence, including large language models and machine learning algorithms, to generate, auto-complete, and review code. They are designed to enhance developer productivity, automate repetitive tasks, and provide intelligent suggestions within the context of your project.
Effective use of AI coding tools requires treating them as pair programming assistants, not as replacements for human judgment. Human oversight remains essential for ensuring code quality, security, and alignment with business requirements.
AI Coding Tools Best Practices
To maximize the benefits and minimize the risks of AI coding tools, follow these actionable best practices:
- Never copy-paste AI code blindly. Always perform manual line-by-line reviews to check for logical flaws and security vulnerabilities.
- Always manually verify and test AI-generated code for security, logic, and efficiency before integrating it into your codebase.
- Use AI coding tools for repetitive tasks, generating boilerplate code, unit tests, or documentation. Let AI handle routine work so you can focus on complex problem-solving.
- Provide detailed, small-scope prompts with clear requirements to AI. The more specific and detailed your prompts, the better the code the AI will produce.
- Never input sensitive data into public AI models. Use secure environments for sensitive work and never allow AI to handle API keys or confidential information directly.
- Clearly disclose AI usage in commit messages and pull request documentation to maintain team transparency and accountability.
- Implement strict review standards for AI-generated code, treating it as untrusted until thoroughly reviewed.
- Break complex tasks into smaller, manageable components to improve AI accuracy and reduce errors.
- Engage in a back-and-forth flow with AI, asking for explanations and refining prompts as needed.
- Leverage AI-native IDEs and tools that provide real-time context and autocomplete for more effective integration.
- Establish project-specific rules in your IDE to ensure consistent styling and patterns across AI sessions.
- Commit code more frequently when using AI tools to allow for quick reversals if needed.
- Maintain a human-in-the-loop approach for code reviews and critical decision points.
- Document the codebase and context early to help AI tools generate higher-quality output.
- Plan your project and codebase before using AI tools to maintain control and improve maintainability.
- Provide comprehensive training on AI tools to maximize their effectiveness and developer productivity.
- Continuously learn and adapt your workflows to keep pace with evolving AI capabilities and best practices.
By following these best practices, teams can harness the power of AI coding tools while maintaining high standards for code quality, security, and collaboration.
Introduction to AI Coding
AI-driven coding is fundamentally transforming the Software Development Life Cycle (SDLC) by leveraging sophisticated artificial intelligence algorithms and machine learning models to assist developers across comprehensive development workflows. Contemporary AI-powered development tools, including intelligent coding assistants and AI-enhanced code completion systems, are meticulously engineered to streamline complex coding tasks, deliver context-aware code suggestions, and automate resource-intensive repetitive processes.
By integrating these advanced AI-driven solutions into established development methodologies, engineering teams can substantially amplify coding efficiency, minimize error-prone implementations, and elevate overall code quality standards through automated best practices enforcement and real-time vulnerability detection.
As organizational demand for rapid deployment cycles and robust software architecture intensifies, AI-powered coding methodologies have become indispensable for modern development operations. These sophisticated tools enable developers to concentrate on complex problem-solving initiatives and scalable architectural decisions, while routine code generation, automated testing, and bug remediation processes are seamlessly handled by machine learning algorithms.
The outcome is a dramatically optimized development pipeline, where high-quality, production-ready code is generated with enhanced velocity and superior accuracy metrics. Whether architecting innovative features or maintaining legacy system integration, AI-driven coding platforms now represent essential infrastructure for development teams committed to maintaining competitive market positioning and delivering enterprise-grade software solutions.
With this foundational understanding, let's explore the main use cases and benefits of AI coding tools.
Main Use Cases and Benefits of AI Coding Tools
AI coding tools are transforming the software development process by enabling developers to generate, auto-complete, and review code using natural language prompts. Here are the main use cases and benefits, organized by key areas:
Productivity Features
- Enhanced Productivity: Automate repetitive tasks and provide intelligent code suggestions to significantly boost developer productivity.
- AI Suggestions: Offer code completions, refactorings, and actionable insights, integrating smoothly into developer workflows.
- Real-Time Code Suggestions: Deliver immediate code completions and live support during programming sessions.
Code Generation
- Generating Code: Efficiently produce code snippets, functions, or complete solutions based on user prompts, while maintaining code quality through systematic review and automated testing.
- Python Code Assistance: Assist with Python code generation, error detection, and productivity enhancements tailored for Python developers.
- Boilerplate and Test Generation: Generate boilerplate code, write tests, fix bugs, and explain unfamiliar code to new developers.
Testing and Debugging
- Writing and Verifying Code: Generate, test, and refine code snippets, ensuring the resulting code meets its intended functionality.
- Debugging and Code Review: Assist with debugging, code formatting, complex code reviews, and architectural suggestions.
- Automated Testing: Tools like TestSprite and Diffblue are examples of AI coding assistants that automatically generate unit, integration, and security tests.
- Test Maintenance: Detect ‘flaky’ tests and automatically update them when code changes.
Collaboration and Support
- Documentation Generation: Generate documentation to help maintain code quality and understanding.
- Accelerated Development: Improve productivity and accelerate software development.
- Focus on Complex Problems: Automate repetitive tasks, allowing developers to focus on more complex issues.
- Automated Code Reviews: Automate code reviews to ensure consistent quality and adherence to coding standards.
- Overcoming the ‘Blank Page Problem’: Provide initial code suggestions to help developers start new tasks.
- Technical Debt Reduction: Autonomously refactor aging legacy code, reducing technical debt.
- Seamless IDE Integration: Integrate seamlessly with popular IDEs for a smoother development experience.
- Collaboration and Support: Offer code suggestions, explanations, test generation, and collaboration tools.
- Developer Enablement: Enhance developers’ capabilities and efficiency without replacing them.
- Rapid Adoption: 65% of developers use AI coding assistants at least weekly, according to recent surveys.
AI coding tools can analyze entire codebases, edit across files, fix bugs, and generate documentation based on natural language prompts. They also provide real-time feedback and suggestions, which can enhance the learning experience for new developers.
However, the use of AI coding assistants has led to an increase in copy-pasted code, indicating a rise in technical debt. Some developers have also expressed concerns that AI coding assistants may produce poorly designed code, complicating long-term maintenance.
To ensure code quality and security, always manually verify and test AI-generated code for security, logic, and efficiency. Never copy-paste AI code blindly; perform manual line-by-line reviews to check for logical flaws and security vulnerabilities, and confirm that the code aligns with its intended functionality.
With these use cases in mind, let's examine how AI coding adoption is impacting software engineering as a whole.
Overview of AI Coding Adoption and Its Effect on Software Engineering
Broad Summary of AI Coding Adoption
The software engineering landscape has undergone a seismic shift as AI coding tools transition from experimental technologies to essential development infrastructure. AI coding tools are now a core part of modern software engineering, with organizations seeking to optimize their development processes by evaluating and adopting the best AI coding tools to meet the demands of contemporary software projects.
Adoption Rates
According to recent industry research, 90% of developers now use AI tools in their workflows, representing a dramatic surge from just 25% adoption rates in early 2023. This widespread integration signals a fundamental change in how software is conceived, written, and maintained.
Integration with Workflows
AI-powered workflows are streamlining software development and enabling more complex project handling by automating repetitive tasks, improving collaboration, and integrating seamlessly with existing processes. Developers now dedicate a median of two hours daily to working with AI tools, demonstrating how deeply these technologies have become woven into everyday development tasks.
This isn’t merely about occasional code suggestions—AI has become an integral part of the development process, from initial architecture planning through deployment and maintenance. Integrating an AI code review tool into your workflow requires configuring repository hooks and defining review policies to ensure the tool fits your team's needs and enforces consistent standards.
AI Coding Assistants: Definition and Capabilities
AI coding assistants represent a category of artificial intelligence tools designed to enhance developer productivity through automated code generation, intelligent suggestions, and contextual programming assistance. AI coding assistants can help with boilerplate code, writing tests, fixing bugs, and explaining unfamiliar code to new developers.
These tools leverage large language models trained on vast codebases to understand programming patterns, suggest completions, and even generate entire functions or modules based on natural language descriptions.
A 'coding agent' is an advanced type of AI-powered tool that acts as an autonomous or semi-autonomous assistant within IDEs like VS Code and JetBrains. Coding agents can execute structured development tasks, plan steps, and automate entire workflows, including building applications based on high-level goals. In addition to coding tasks, AI agents can manage deployment gates and autonomously roll back failing releases, streamlining deployment and release management for engineering teams.
An AI coding assistant or AI assistant can provide relevant suggestions tailored to the project context and help maintain the same style as the existing codebase, ensuring consistency and efficiency. These assistants also help overcome the ‘blank page problem' by providing initial code suggestions, making it easier for developers to start new tasks.
Developer Experience and Tool Integration
Integration with development environments is critical for maximizing the benefits of AI coding. IDE integration, VS Code extension, and code extension support enable seamless workflow, allowing developers to access AI-powered features directly within their preferred tools.
Notably, Amazon Q Developer focuses on AWS-native architectures and integrates with IDEs, Tabnine uses deep learning to adapt to a developer's coding style, and Replit offers a browser-based AI coding platform with interactive development and AI-powered assistance.
Productivity and Code Quality Impacts of AI Coding Tools
The transformative effects extend beyond individual productivity gains. Teams report accelerated feature delivery cycles, reduced time-to-market for new products, and improved code consistency across projects.
However, this rapid adoption has also introduced new challenges around code quality assurance, security validation, and maintaining engineering standards when AI-generated code comprises significant portions of production systems. There is a growing need for robust error handling and error detection, as AI tools can assist in fixing bugs but require oversight to ensure software reliability and maintainability.
Code review and maintainability are also evolving as AI-generated code becomes more prevalent. Supporting multiple languages and ensuring programming language compatibility in AI coding tools is essential for teams working across diverse technology stacks.
When selecting AI coding tools, engineering leaders should consider the role of development tools, the capabilities of different AI models, and the significance of high-quality training data for accurate and context-aware code generation. The choice of an AI coding assistant should also take into account the team's size and the specific programming languages being used.
Developer experience is also shaped by the learning curve associated with adopting AI coding tools. Even experienced developers face challenges when working with an entire codebase and reviewing code generated by AI, requiring time and practice to fully leverage these technologies. Developers have reported mixed experiences with AI coding tools, with some finding them helpful for boilerplate code and others experiencing limitations in more complex scenarios. Developer productivity can be further enhanced with AI-native intelligence tools that offer actionable insights and metrics.
As developers create new workflows and approaches with the help of AI, AI chat features are increasingly integrated into coding environments to provide real-time assistance, answer contextual questions, and support debugging.
Engineering leaders must now navigate this new landscape, balancing the undeniable productivity benefits of AI tools with the responsibility of maintaining code quality, security, and team expertise. Many AI coding tools offer a free tier or free version, making them accessible for individual developers, while pricing varies widely across free, individual, and enterprise plans. The organizations that succeed will be those that develop sophisticated measurement frameworks to understand and optimize their AI coding impact.
With this context in mind, let's explore how AI-generated code is changing the development process in detail.
Understanding AI Generated Code
How AI Generates Code
AI generated code is fundamentally reshaping the software development landscape by introducing sophisticated algorithms that analyze vast datasets, predict optimal coding patterns, and deliver context-aware code generation at unprecedented scales.
Leveraging advanced AI coding tools powered by natural language processing (NLP) and machine learning (ML) algorithms, development teams can now generate high-quality code snippets, receive intelligent code suggestions, and benefit from advanced code completion capabilities that analyze project context, coding patterns, and historical data to deliver precise recommendations.
AI performs exceptionally well at generating code, documentation, and tests effectively, enhancing the development process and code comprehension. AI excels at routine and consistency tasks, such as enforcing coding standards and automating repetitive work, but human judgment remains essential for addressing more complex or nuanced issues.
Integration with IDEs
Modern AI coding assistants integrate seamlessly with popular Integrated Development Environments (IDEs) such as Visual Studio Code (VS Code), Visual Studio, IntelliJ IDEA, and PyCharm, making it increasingly straightforward to incorporate AI powered code completion into daily development workflows.
A crucial feature for effective code development is robust context management, which allows these tools to understand and adapt to project environments, ensuring that code suggestions are relevant and accurate.
Productivity Benefits
Benefits of AI Coding Tools:
- Accelerate code generation and prototyping cycles
- Enhance overall code quality with real-time suggestions and automated refactoring
- Provide comprehensive code explanations and documentation
- Reduce syntax errors and logical inconsistencies
- Promote code consistency and maintainability
- Support multiple programming languages and frameworks
- Automate repetitive coding tasks, freeing developers for higher-level work
AI coding tools are transforming the software development process by enabling developers to generate, auto-complete, and review code using natural language prompts.
Challenges and Risks
Challenges and Risks of AI Coding Tools:
To better understand how AI tools can both benefit and challenge software teams, see our comprehensive guide to developer productivity tools.
- May lack nuanced understanding of domain-specific business logic or legacy system constraints
- Can introduce security vulnerabilities if not properly configured or reviewed
- Potential for increased technical debt if generated code is not aligned with long-term architectural goals
- Require comprehensive oversight, including code reviews and automated testing
- Developers may face a learning curve in reviewing and integrating AI-generated code
Limitations of AI Coding Assistants
Understanding the limitations of AI coding assistants is crucial, as they may not always produce optimal solutions for complex problems. While these tools excel at automating routine tasks and providing initial code drafts, they may struggle with highly specialized algorithms, intricate architectural decisions, or unique business requirements.
In these cases, human reviewers play an essential role in handling complex, judgment-based aspects of the code review process, such as architectural decisions and logic validation. A human-in-the-loop approach is essential for the most effective AI code review implementations, ensuring quality and context are maintained.
Quality Assurance and Oversight
To maximize benefits and minimize operational risks, it becomes essential to systematically select AI coding tools that align precisely with your development team's technical requirements, preferred technology stack, and established development environment configurations.
Implementing systematic practices for regularly reviewing, testing, and validating AI generated code against established organizational standards is critical. Even the most sophisticated AI coding assistants require comprehensive oversight mechanisms to guarantee that generated code meets stringent organizational standards for security, performance, scalability, and readability.
With a clear understanding of how AI generates code and its associated challenges, let's move on to the expanding ecosystem of AI tools for coding.
Overview of AI Tools for Coding
The Expanding Ecosystem
The contemporary ecosystem of AI-driven development platforms demonstrates unprecedented expansion, delivering sophisticated algorithmic solutions meticulously engineered to address diverse computational development paradigms. These advanced AI coding tools and frameworks are especially valuable for managing multiple files during larger migration projects and incremental development work, streamlining complex tasks that span across extensive codebases.
Industry-leading intelligent coding frameworks such as GitHub Copilot, Tabnine, and Augment Code have established foundational benchmarks for advanced code synthesis and automated completion mechanisms, achieving seamless architectural integration with extensively utilized development environments including Visual Studio Code (VS Code) and JetBrains IDEs.
Key Features and Capabilities
These AI-powered coding assistants harness sophisticated natural language processing algorithms to interpret and analyze natural language prompts, empowering development teams to synthesize comprehensive code snippets and intricate functional implementations through descriptive intent articulation.
Common Features of AI Coding Tools:
- Automated code generation and completion
- Intelligent code suggestions and refactoring
- Automated code review and bug detection
- Security vulnerability analysis
- Documentation generation
- Integration with popular IDEs and version control systems
- Analyzing and refactoring existing code, enabling seamless adoption within current IDEs and version control systems
Advanced Operational Features
Transcending fundamental code generation capabilities, contemporary AI-enhanced development platforms now orchestrate advanced operational features including:
- Automated code review systems
- Predictive bug detection algorithms
- Comprehensive security vulnerability analysis frameworks
Many AI code review and generation tools process code on external servers, raising important considerations around data security and privacy. It is crucial for engineering teams to understand whether their code is being processed on external servers or internal infrastructure, as each deployment model carries different security implications. Evaluating where code is handled helps organizations mitigate risks associated with sensitive information exposure and comply with internal security policies.
This multifaceted approach not only optimizes code quality metrics but simultaneously accelerates development lifecycle velocity by implementing proactive issue identification protocols during early development phases.
Selecting the Right Tool
When strategically evaluating optimal AI toolchain selection for organizational deployment, critical consideration parameters encompass compatibility matrices with preferred programming language ecosystems, the comprehensive capability spectrum of tools within your development environment architecture, and the specific technical requirements governing your project portfolios.
Prompt engineering is a key strategy for improving the quality and relevance of AI interactions. Developers should prioritize prompt engineering to ensure AI tools understand their requirements clearly.
Through strategic implementation of appropriate AI coding platforms, development teams can achieve enhanced precision-driven code suggestions, maintain elevated code quality standards, and systematically optimize their software development workflow architectures.
With a solid grasp of the available tools, let's now focus on how to measure the impact of AI coding in your organization.
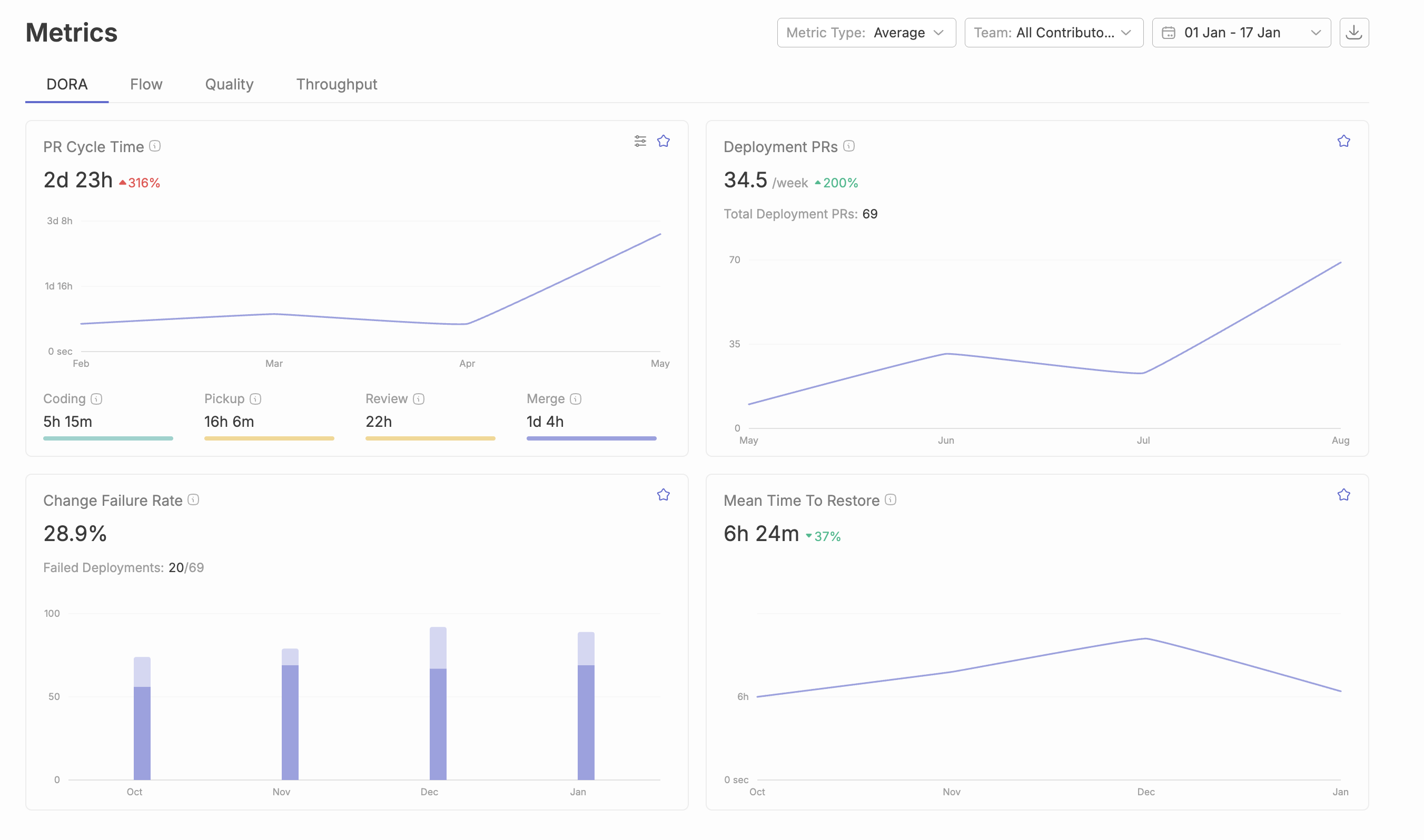
Key Metrics for Measuring AI Coding Impact
Developer Velocity and Productivity Metrics
Measuring the velocity impact of AI coding tools requires a multifaceted approach that captures both quantitative output and qualitative improvements in developer experience. The most effective metrics combine traditional productivity indicators with AI-specific measurements that reflect the new realities of assisted development.
- Code Generation Speed: Track the time from task assignment to first working implementation, comparing pre-AI and post-AI adoption periods while controlling for task complexity.
- Feature Delivery Velocity: PR cycle time, measure story points completed per sprint, features shipped per quarter, or time-to-market for new capabilities.
- Developer Flow State Preservation: Measure context switching frequency, time spent in deep work sessions, and developer-reported satisfaction with their ability to maintain concentration.
- Task Completion Rates: Analyze completion rates across different complexity levels to reveal where AI tools provide the most value.
Code Quality and Reliability Improvements
Quality metrics must evolve to account for the unique characteristics of AI-generated code while maintaining rigorous standards for production systems.
- Defect Density Analysis: Compare AI-assisted versus human-only code for bug rates and logic errors.
- Security Vulnerability Detection: Use automated security scanning tools to monitor for vulnerabilities in AI-generated code.
- Code Review Efficiency: Measure review cycle time, comments per review, and reviewer confidence ratings.
- Pull Requests Transparency: Clearly disclose AI usage in commit messages and pull request documentation to maintain team transparency.
- Technical Debt Accumulation: Track code maintainability scores, architectural compliance ratings, and refactoring frequency.
Team Performance and Developer Experience
- Skill Development Trajectories: Monitor junior developer progression rates, knowledge transfer effectiveness, and skill acquisition.
- Collaboration Quality Indicators: Track code review engagement levels, knowledge sharing session frequency, and cross-team collaboration effectiveness.
- Developer Satisfaction and Retention: Survey developers about their experience with AI tools, focusing on perceived value and impact on job satisfaction.
- Cognitive Load Assessment: Use surveys and focus groups to assess changes in mental workload and stress levels.
Learn more about key performance indicators for software development teams.
With these metrics in place, organizations can better understand the ROI and business impact of AI coding tools.
ROI and Business Impact Analysis
Cost-Benefit Framework for AI Coding Tools
Establishing a comprehensive cost-benefit framework for AI coding tools requires careful consideration of both direct financial impacts and indirect organizational benefits.
- Direct Cost Analysis: Account for tool licensing fees, infrastructure requirements, and integration expenses.
- Productivity Value Calculation: Translate time savings into financial impact based on developer salaries and team size.
- Quality Impact Monetization: Calculate cost savings from reduced bug rates and technical debt remediation.
- Competitive Advantage Quantification: Assess the strategic value of faster time-to-market and improved innovation capacity.
Long-term Strategic Value
- Talent Acquisition and Retention Benefits: Organizations offering modern AI-enhanced development environments attract higher-quality candidates and experience reduced turnover rates.
- Innovation Acceleration Capacity: AI tools free developers from routine tasks, enabling focus on creative problem-solving and experimental projects.
- Scalability and Growth Enablement: AI tools help smaller teams achieve output levels previously requiring larger headcounts.
- Technical Debt Management: AI tools generate more consistent, well-documented code that aligns with established patterns.
With a clear understanding of ROI, let's move on to best practices for implementing and measuring AI coding tools in your organization.
Implementation Best Practices and Measurement Frameworks
Establishing Baseline Metrics
To measure the impact of AI coding tools, follow these steps:
- Pre-Implementation Data Collection: Collect data for 3-6 months on developer velocity, code quality, and developer satisfaction.
- Metric Standardization Protocols: Define clear criteria for AI-assisted vs. traditional development work and implement automated tooling.
- Control Group Establishment: Maintain teams using traditional methods alongside AI-assisted teams for comparison.
- Measurement Cadence Planning: Implement weekly, monthly, and quarterly reviews to capture both short-term and long-term impacts.
Monitoring and Optimization Strategies
- Real-time Dashboard Implementation: Track daily metrics including AI tool engagement rates and code generation volumes.
- Regular Assessment Cycles: Combine quantitative analysis with qualitative feedback collection in retrospectives and business reviews.
- Optimization Feedback Loops: Analyze patterns in successful AI-assisted development and document best practices.
- Adaptation and Scaling Protocols: Regularly evaluate new AI coding tools and features, and develop frameworks for scaling successful implementations.
The measurement and optimization of AI coding impact represents an ongoing journey rather than a destination. Organizations that invest in comprehensive measurement frameworks, maintain focus on both quantitative and qualitative outcomes, and continuously adapt their approaches will maximize the transformative potential of AI-assisted development while maintaining the engineering excellence that drives long-term success.
With implementation best practices in place, let's discuss how to integrate AI coding tools with your existing development ecosystem.
Integration with Existing Tools
Seamless Integration with Development Ecosystems
The seamless integration of AI-driven coding solutions with established development ecosystems and sophisticated workflow architectures represents a fundamental paradigm shift in maximizing computational efficiency and developer productivity across enterprise-scale software development initiatives.
Key Integration Features:
- Extension frameworks and plugin architectures for IDEs (e.g., Visual Studio Code, IntelliJ IDEA)
- Context-aware code completion algorithms and real-time intelligent code suggestion engines
- Integration with distributed version control systems (e.g., Git, Mercurial, Subversion)
- Automated code review processes and intelligent merge conflict resolution
Through strategic embedding of AI-powered development tools into established daily workflow patterns, organizations can systematically enhance coding efficiency metrics, accelerate code review cycles, optimize quality assurance processes, and ensure consistent application of industry best practices.
With integration strategies in mind, let's examine how AI-powered code review and feedback can further improve your workflows.
Code Review and Feedback in AI Coding Workflows
AI-Powered Code Review and Feedback
Incorporating AI-powered coding tools and automated code analysis systems into code review and feedback processes is fundamentally transforming how development teams ensure code quality standards, maintainability, and security compliance throughout the comprehensive Software Development Life Cycle (SDLC).
Benefits of AI-Driven Code Review:
- Automated detection of syntax errors, logical inconsistencies, and security vulnerabilities
- Actionable code suggestions and best practice recommendations
- Real-time optimization insights within IDEs
- Reduced reliance on manual reviews and accelerated CI/CD pipeline efficiency
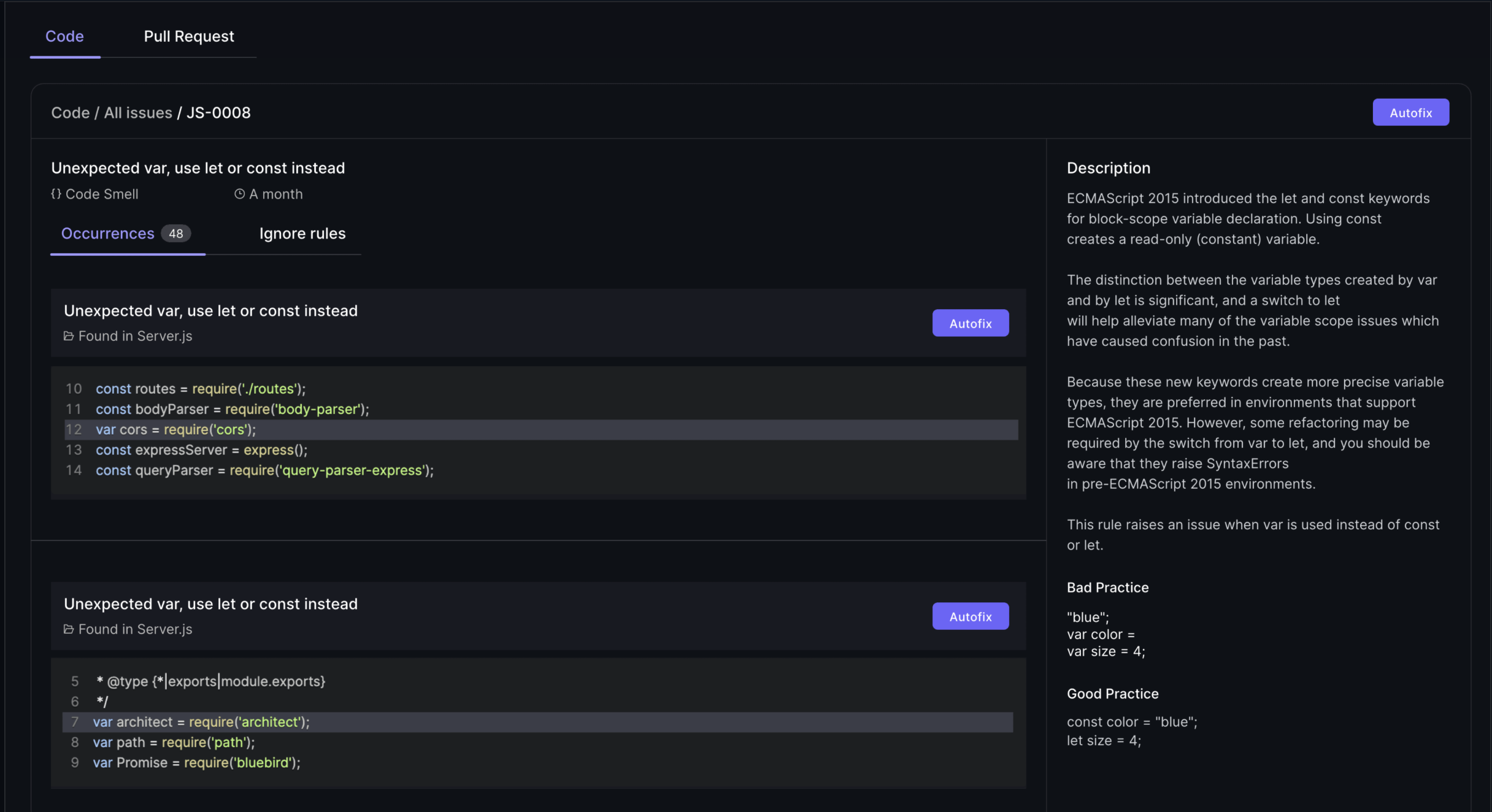
By leveraging AI-powered code review systems and intelligent static analysis tools, development teams can maintain a consistently high level of code quality, architectural integrity, and security posture, even as the pace of agile development iterations increases.
With robust code review processes in place, let's address the security considerations unique to AI-generated code.
Security Considerations in AI Generated Code
Security Challenges and Best Practices
AI-generated code transforms development workflows by delivering remarkable efficiency gains and reducing human error rates across software projects. However, this technological advancement introduces a complex landscape of security challenges that development teams must navigate carefully.
Security Best Practices:
- Establish comprehensive code review processes and rigorous testing protocols for AI-generated code
- Leverage advanced security-focused capabilities embedded within modern AI coding platforms
- Implement multiple layers of protection, including penetration testing, static code analysis, and code auditing
- Continuously monitor AI-generated code against baseline security metrics
By integrating security considerations into every stage of the AI-assisted development process, organizations can effectively harness the transformative power of AI-generated code while maintaining the robust security posture and reliability that modern software solutions demand.
With security addressed, let's look at how code snippets can be used strategically in AI coding workflows.
Using Code Snippets in AI Coding Workflows
Code snippets have become a strategic asset in modern AI-driven software development, enabling engineering teams to accelerate coding tasks while maintaining high standards of code quality and consistency. These reusable fragments of code are intelligently generated and adapted by AI coding assistants based on the project's historical data, architectural context, and team-specific coding practices.
For engineering leaders, leveraging AI-powered code snippet management translates into measurable productivity gains by reducing repetitive manual coding, minimizing integration errors, and enforcing organizational coding standards across diverse teams and projects.
Leading AI coding platforms such as GitHub Copilot and Tabnine employ advanced machine learning models that analyze extensive codebases and developer interactions to deliver precise, context-aware code suggestions within popular integrated development environments (IDEs) like Visual Studio Code and JetBrains. These tools continuously refine their recommendation engines by learning from ongoing developer feedback, ensuring that the generated snippets align with both project-specific requirements and broader enterprise coding guidelines.
By embedding AI-enhanced snippet workflows into the development lifecycle, organizations can shift engineering efforts from routine code creation toward solving complex architectural challenges, optimizing system performance, and advancing innovation. This approach also fosters improved collaboration through standardized code sharing and version control integration, ensuring that teams operate with a unified codebase and adhere to best practices.
Ultimately, the adoption of AI-assisted code snippet management supports accelerated delivery timelines, higher code reliability, and enhanced developer satisfaction—key metrics for engineering leaders aiming to drive competitive advantage in software delivery.
With code snippet strategies in place, let's compare the leading AI coding assistants available today.
Comparative Analysis of AI Coding Assistants
| AI Coding Assistant |
Key Strengths |
Deployment Options |
Programming Language Support |
Integration & IDE Support |
Unique Features |
Ideal Use Cases |
Considerations for Engineering Leaders |
| GitHub Copilot |
Advanced neural network-based code completion; seamless GitHub and VS Code integration |
Cloud-based |
Wide language support including Python, JavaScript, TypeScript, and more |
Visual Studio Code, Visual Studio, JetBrains IDEs |
Real-time code suggestions, PR summaries, code explanations |
Rapid prototyping, teams prioritizing speed and ease of adoption |
Limited context window can challenge large or legacy codebases; best suited for modern codebases |
| Tabnine |
Privacy-focused; adapts to individual and team coding styles; supports deep learning models |
Cloud and self-hosted |
Supports multiple programming languages |
VS Code, JetBrains, other popular IDEs |
Intelligent code refactoring, code explanation, customizable models |
Organizations with stringent security requirements, regulated industries |
Slightly slower response times; self-hosting requires infrastructure investment |
| Augment Code |
Architectural context engine; semantic dependency graph for large codebases |
Cloud-based |
Supports large, complex repositories with multiple languages |
VS Code, JetBrains |
Multi-file refactoring; deep architectural understanding; advanced AI code review |
Enterprises managing legacy systems and distributed architectures |
Initial indexing time required; cloud-based processing may raise security concerns and impact developer productivity |
| Amazon Q Developer |
AWS-native architecture understanding; integrated security scanning |
Cloud-based |
Focus on AWS services and common programming languages |
VS Code, JetBrains, AWS Console |
Security vulnerability detection; CloudFormation and CDK troubleshooting |
Teams heavily using AWS infrastructure |
Limited value outside AWS ecosystem; weaker understanding of custom architectures |
| Claude Code |
Advanced reasoning and autonomous coding capabilities; multi-agent workflows |
Cloud-based |
Supports multiple popular programming languages |
VS Code, JetBrains, other IDEs, and software engineering intelligence platforms |
Autonomous coding agents; enhanced context management; planning mode |
Complex projects requiring extended context and autonomous coding |
Newer platform with evolving features; teams must adapt to agent-based workflows |
| JetBrains AI Assistant |
Deep IDE integration; AST-aware code understanding; test generation |
Cloud-based |
Java, Kotlin, Python, Go, JavaScript, and other major languages |
JetBrains IDEs only |
Refactoring guidance, debugging assistance, pattern-based test generation |
Teams standardized on JetBrains IDEs; regulated environments |
No VS Code support; moderate autocomplete speed; limited repo-wide architectural context |
| Cursor |
Fast autocomplete; targeted context queries via @mentions |
Cloud-based (standalone VS Code fork) with integration options for generative AI developer tools |
Supports multiple programming languages |
Standalone VS Code fork |
Fast response times; multi-file editing; targeted questions |
Solo developers and small teams working on modern codebases |
No repository-wide semantic understanding; requires switching editors |
This comparative table provides engineering leaders with a holistic view of top AI coding assistants, highlighting strengths, deployment models, integration capabilities, and considerations to guide informed decision-making aligned with organizational needs and project complexity.
With a comparison of leading tools complete, let's explore the emerging trends and technologies shaping the future of AI coding.
Emerging Trends and Technologies in AI Coding
The software development landscape is undergoing a profound transformation driven by emerging AI technologies that reshape how teams generate, review, and maintain code. Among the most significant trends is the adoption of local large language models (LLMs), which enable AI-powered coding assistance to operate directly within on-premises infrastructure. This shift addresses critical concerns around data privacy, security compliance, and latency, making AI coding tools more accessible for organizations with stringent regulatory requirements.
Natural language processing advancements now allow AI tools to translate plain-language business specifications into high-quality, production-ready code without requiring deep expertise in programming languages. This democratizes software development, accelerates onboarding, and fosters collaboration between technical and non-technical stakeholders.
AI-driven code quality optimization is becoming increasingly sophisticated, with models capable of analyzing entire codebases to identify security vulnerabilities, enforce coding standards, and predict failure-prone areas. Integration with continuous integration and continuous deployment (CI/CD) pipelines enables automated generation of comprehensive test cases, ensuring functional and non-functional requirements are met while maintaining optimal performance.
For engineering leaders, embracing these AI innovations means investing in platforms that not only enhance coding efficiency but also proactively manage technical debt and security risks. Teams that adopt AI-enhanced development workflows position themselves to achieve superior software quality, faster delivery cycles, and sustainable scalability in an increasingly competitive market.
With an eye on the future, let's discuss how to customize AI coding workflows for your team's unique needs.
Customizing AI Coding Workflows
Customizing AI coding workflows is essential for software engineers and engineering leaders who want to unlock the full potential of AI-assisted coding. By tailoring AI tools to fit the unique needs of your team and development process, you can significantly enhance code quality, streamline repetitive tasks, and accelerate delivery timelines.
AI coding assistants like Claude Code can be seamlessly integrated into existing development workflows, providing real-time AI assistance for everything from generating boilerplate code to reviewing code for style violations and complex logic errors. To get the most value from AI-assisted coding, start by identifying the stages in your workflow where AI tools can have the greatest impact—such as automating repetitive coding tasks, flagging style inconsistencies, or offering feedback on intricate business logic.
Custom workflows might include configuring AI tools to align with your team’s coding standards, setting up automated code review triggers, or using AI to generate documentation and tests for new features. By leveraging AI coding assistants in a way that complements human expertise, software engineers can focus on higher-value problem solving while AI handles routine or time-consuming tasks. This synergy not only improves code quality but also fosters a more efficient and effective development process.
Ultimately, the key to successful AI-assisted coding lies in continuous refinement: regularly review how AI tools are performing within your workflows, gather feedback from your team, and adjust configurations to ensure that AI assistance is always aligned with your evolving business needs and technical goals.
With customized workflows in place, staying up-to-date with AI advancements is the next step to maintaining a competitive edge.
Staying Up-to-Date with AI Advancements
In the fast-moving world of AI-assisted coding, staying up-to-date with the latest AI tools, models, and best practices is critical for software engineers who want to leverage AI effectively in their development workflows. The landscape of AI coding is constantly evolving, with new AI models and features emerging that can dramatically improve productivity, code quality, and the overall development process.
To keep pace, developers should actively participate in online forums, join AI and software engineering communities, and attend industry conferences or webinars focused on AI-assisted development. Engaging with peers and thought leaders provides valuable insights into how others are integrating AI tools into their workflows and overcoming common challenges.
Experimentation is equally important—try out new AI tools and features as they become available, and evaluate how they fit into your team’s specific use cases. By continuously learning and adapting, you can ensure that your development workflows remain optimized and that you are leveraging AI to its fullest potential.
Staying informed about the latest advancements in AI-assisted coding not only helps you maintain a competitive edge but also empowers you to adopt best practices that drive better performance, security, and code quality across your projects.
With a commitment to continuous learning, let's conclude with a summary of the key takeaways for AI-assisted coding.
Conclusion
AI-assisted coding is a powerful tool that is transforming the software development landscape. By leveraging advanced AI tools such as Claude Code, software engineers can dramatically improve code quality, accelerate the development process, and boost overall productivity. To fully realize these benefits, it’s essential to customize your AI coding workflows, stay current with the latest AI advancements, and commit to continuous learning and improvement.
Embracing AI-assisted coding and following best practices enables teams to create better software, faster and more efficiently. Whether you’re an experienced software engineer or just beginning your journey, integrating AI into your development process is now an essential skill for success in today’s dynamic software development environment.
Additional Resources
For those looking to deepen their expertise in AI-assisted coding and make the most of AI tools in their development workflows, a wealth of resources is available. Online courses from providers like DeepLearning.AI offer comprehensive introductions to AI-assisted coding and the latest AI tools. Industry conferences and local meetups provide opportunities to network, share experiences, and learn about emerging best practices.
Active participation in online communities such as GitHub and Stack Overflow can help you stay informed about new developments, troubleshoot challenges, and exchange ideas with other developers leveraging AI. Exploring popular AI tools like GitHub Copilot, Cursor, and Claude Code can also provide hands-on experience with AI-assisted coding, code review, and the generation of boilerplate code.
By taking advantage of these resources and continuously refining your approach, you can stay at the forefront of AI-assisted development, ensuring your skills and workflows remain aligned with industry best practices and the latest technological advancements.















.png)