DORA metrics are a standard set of DevOps metrics used to evaluate software delivery performance. This guide explains what DORA metrics are, why they matter, and how to use them in 2026.
This practical guide is designed for engineering leaders and DevOps teams who want to understand, measure, and improve their software delivery performance using DORA metrics. The scope of this guide includes clear definitions of each DORA metric, practical measurement strategies, benchmarking against industry standards, and best practices for continuous improvement in 2026.
Understanding DORA metrics is critical for modern software delivery because they provide a proven, data-driven framework for measuring both the speed and stability of your engineering processes. By leveraging these metrics, organizations can drive better business outcomes, improve team performance, and build more resilient systems.
Over the last decade, the way engineering teams measure performance has fundamentally shifted. What began as DevOps Research and Assessment (DORA) work at Google Cloud around 2014 has evolved into the industry standard for understanding software delivery performance. DORA originated as a team at Google Cloud specifically focused on assessing DevOps performance using a standard set of metrics. The DORA research team surveyed more than 31,000 professionals over seven years to identify what separates elite performers from everyone else—and the findings reshaped how organizations think about shipping software.
The research revealed something counterintuitive: elite teams don’t sacrifice speed for stability. They excel at both simultaneously. This insight led to the definition of four key DORA metrics: Deployment Frequency, Lead Time for Changes, Change Failure Rate, and Time to Restore Service (commonly called MTTR). As of 2026, DORA metrics have expanded to a five-metric model to account for modern development practices and the impact of AI tools, with Reliability emerging as a fifth signal, particularly for organizations with mature SRE practices. These key DORA metrics serve as key performance indicators for software delivery and DevOps performance, measuring both velocity and stability, and now also system reliability.
These metrics focus specifically on team-level software delivery velocity and stability. They’re not designed to evaluate individual productivity, measure customer satisfaction, or assess whether you’re building the right product. What they do exceptionally well is quantify how efficiently your development teams move code from commit to production—and how gracefully they recover when things go wrong. Standardizing definitions for DORA metrics is crucial to ensure meaningful comparisons and avoid misleading conclusions.
The 2024–2026 context makes these metrics more relevant than ever. Organizations that track DORA metrics consistently outperform on revenue growth, customer satisfaction, and developer retention. By integrating these metrics, organizations gain a comprehensive understanding of their delivery performance and system reliability. Elite teams deploying multiple times per day with minimal production failures aren’t just moving faster—they’re building more resilient systems and happier engineering cultures. The data from recent State of DevOps trends confirms that high performing teams ship 208 times more frequently than low performers while maintaining one-third the failure rate. Engaging team members in the goal-setting process for DORA metrics can help mitigate resistance and foster collaboration. Implementing DORA metrics can also help justify process improvement investments to stakeholders, and helps identify best and worst practices across engineering teams.
For engineering leaders who want to measure performance without building custom ETL pipelines or maintaining in-house scripts, platforms like Typo automatically calculate DORA metrics by connecting to your existing SDLC tools. Instead of spending weeks instrumenting your software development process, you can have visibility into your delivery performance within hours.
The bottom line: if you’re responsible for how your engineering teams deliver software, understanding and implementing DORA metrics isn’t optional in 2026—it’s foundational to every improvement effort you’ll pursue.
The four core DORA metrics are deployment frequency, lead time for changes, change failure rate, and time to restore service. These metrics are essential indicators of software delivery performance. In recent years, particularly among SRE-focused organizations, Reliability has gained recognition as a fifth key DORA metric that evaluates system uptime, error rates, and overall service quality, balancing velocity with uptime commitments.
Together, these five key DORA metrics split into two critical aspects of software delivery: throughput (how fast you ship) and stability (how reliably you ship). Deployment Frequency and Lead Time for Changes represent velocity—your software delivery throughput. Change Failure Rate, Time to Restore Service, and Reliability represent stability—your production stability metrics. The key insight from DORA research is that elite teams don’t optimize one at the expense of the other.
For accurate measurement, these metrics should be calculated per service or product, not aggregated across your entire organization. Standardizing definitions for DORA metrics is crucial to ensure meaningful comparisons and avoid misleading conclusions. A payments service with strict compliance requirements will naturally have different patterns than a marketing website. Lumping them together masks the reality of each team’s ability to deliver. The team's ability to deliver code efficiently and safely is a key factor in their overall performance metrics.
The following sections define each metric, explain how to calculate it in practice, and establish what “elite” versus “low” performance typically looks like in 2024–2026.
Deployment Frequency measures how often an organization successfully releases code to production—or to a production-like environment that users actually rely on—within a given time window. It’s the most visible indicator of your team’s delivery cadence and CI/CD maturity.
Elite teams deploy on-demand, typically multiple times per day. High performers deploy somewhere between daily and weekly. Medium performers ship weekly to monthly, while low performers struggle to release more than once per month—sometimes going months between production deployments. These benchmark ranges come directly from recent DORA research across thousands of engineering organizations, illustrating key aspects of developer experience.
The metric focuses on the count of deployment events over time, not the size of what’s being deployed. A team shipping ten small changes daily isn’t “gaming” the metric—they’re practicing exactly the kind of small-batch, low-risk delivery that DORA research shows leads to better outcomes. What matters is the average number of times code reaches production in a meaningful time window.
Consider a SaaS team responsible for a web application’s UI. They’ve invested in automated testing, feature flags, and a robust CI/CD pipeline. On a typical Tuesday, they might push four separate changes to production: a button color update at 9:00 AM, a navigation fix at 11:30 AM, a new dashboard widget at 2:00 PM, and a performance optimization at 4:30 PM. Each deployment is small, tested, and reversible. Their Deployment Frequency sits solidly in elite territory.
Calculating this metric requires counting successful deployments per day or week from your CI/CD tools, feature flag systems, or release pipelines. Typo normalizes deployment events across tools like GitHub Actions, GitLab CI, CircleCI, and ArgoCD, providing a single trustworthy Deployment Frequency number per service or team—regardless of how complex your technology stack is.
Lead Time for Changes measures the elapsed time from when a code change is committed (or merged) to when that change is successfully running in the production environment. It captures your end-to-end development process efficiency, revealing how long work sits waiting rather than flowing.
There’s an important distinction here: DORA uses the code-change-based definition, measuring from commit or merge to deploy—not from when an issue was created in your project management tool. The latter includes product and design time, which is valuable to track separately but falls outside the DORA framework.
Elite teams achieve Lead Time under one hour. High performers land under one day. Medium performers range from one day to one week. Low performers often see lead times stretching to weeks or months. That gap represents orders of magnitude in competitive advantage for software development velocity.
The practical calculation requires joining version control commit or merge timestamps with production deployment timestamps, typically using commit SHAs or pull request IDs as the linking key. For example: a PR is opened Monday at 10:00 AM, merged Tuesday at 4:00 PM, and deployed Wednesday at 9:00 AM. That’s 47 hours of lead time—placing this team solidly in the “high performer” category but well outside elite territory.
Several factors commonly inflate Lead Time beyond what’s necessary. Slow code reviews where PRs wait days for attention. Manual quality assurance stages that create handoff delays. Long-running test suites that block merges. Manual approval gates. Waiting for weekly or bi-weekly release trains instead of continuous deployment. Each of these represents an opportunity to identify bottlenecks and accelerate flow.
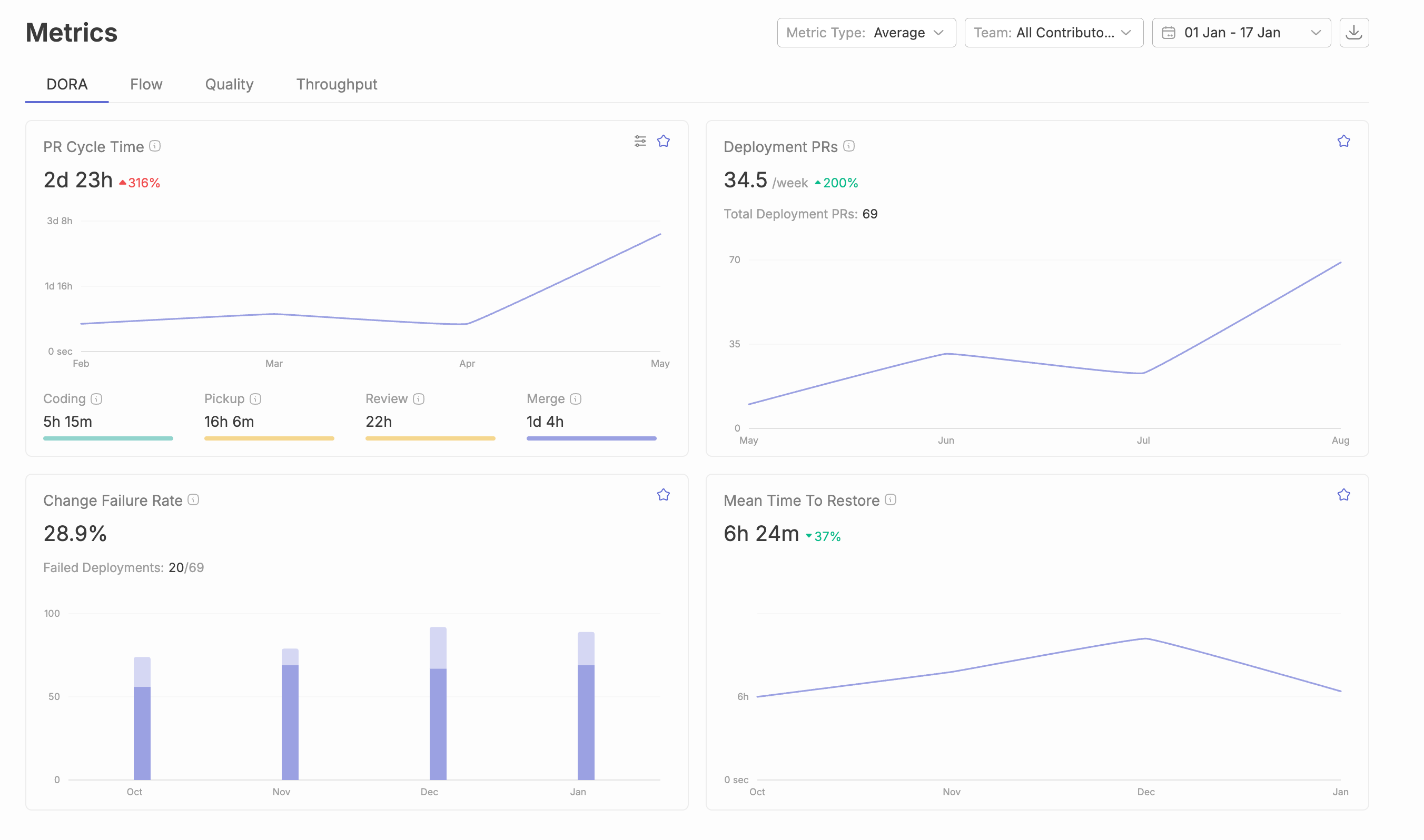
Typo breaks Cycle Time down by stage—coding, pickup, review & merge —so engineering leaders can see exactly where hours or days disappear. Instead of guessing why lead time is 47 hours, you’ll know that 30 of those hours were waiting for review approval.
Change Failure Rate quantifies the percentage of production deployments that result in a failure requiring remediation. This includes rollbacks, hotfixes, feature flags flipped off, or any urgent incident response triggered by a release. It’s your most direct gauge of code quality reaching production.
Elite teams typically keep CFR under 15%. High performers range from 16% to 30%. Medium performers see 31% to 45% of their releases causing issues. Low performers experience failure rates between 46% and 60%—meaning nearly half their deployments break something. The gap between elite and low here translates directly to customer trust, developer stress, and operational costs.
Before you can measure CFR accurately, your organization must define what counts as a “failure.” Some teams define it as any incident above a certain severity level. Others focus on user-visible outages. Some include significant error rate spikes detected by monitoring. The definition matters less than consistency—pick a standard and apply it uniformly across your deployment processes.
The calculation is straightforward: divide the number of deployments linked to failures by the total number of deployments over a period. For example, over the past 30 days, your team completed 25 production deployments. Four of those were followed by incidents that required immediate action. Your CFR is 4 ÷ 25 = 16%, putting you at the boundary between elite and high performance.
High CFR often stems from insufficient automated testing, risky big-bang releases that bundle many changes, lack of canary or blue-green deployment patterns, and limited observability that delays failure detection. Each of these is addressable with focused improvement efforts.
Typo correlates incidents from systems like Jira or Git back to the specific deployments and pull requests that caused them. Instead of knowing only that 16% of releases fail, you can see which changes, which services, and which patterns consistently create production failures.
Time to Restore Service measures how quickly your team can fully restore normal service after a production-impacting failure is detected. You’ll also see this called Mean Time to Recover or simply MTTR, though technically DORA uses median rather than mean to handle outliers appropriately.
Elite teams restore service within an hour. High performers recover within one day. Medium performers take between one day and one week to resolve incidents. Low performers may struggle for days or even weeks per incident—a situation that destroys customer trust and burns out on-call engineers.
The practical calculation uses timestamps from your incident management tools: the difference between when an incident started (alert fired or incident created) and when it was resolved (service restored to agreed SLO). What matters is the median across incidents, since a single multi-day outage shouldn’t distort your understanding of typical recovery capability.
Consider a concrete example: on 2025-11-03, your API monitoring detected a latency spike affecting 15% of requests. The on-call engineer was paged at 2:14 PM, identified a database query regression from the morning’s deployment by 2:28 PM, rolled back the change by 2:41 PM, and confirmed normal latency by 2:51 PM. Total time to restore service: 37 minutes. That’s elite-level incident management in action.
Several practices materially shorten MTTR: documented runbooks that eliminate guesswork, automated rollback capabilities, feature flags that allow instant disabling of problematic code, and well-structured on-call rotations that ensure responders are rested and prepared. Investment in observability also pays dividends—you can’t fix what you can’t see.
Typo tracks MTTR trends across multiple teams and services, surfacing patterns like “most incidents occur Fridays after 5 PM UTC” or “70% of high-severity incidents are tied to the checkout service.” This context transforms incident response from reactive firefighting to proactive improvement opportunities.
As of 2026, DORA metrics include Deployment Frequency, Lead Time for Changes, Change Failure Rate, Failed Deployment Recovery Time (MTTR), and Reliability.
While the original DORA research focused on four metrics, as of 2026, DORA metrics include Deployment Frequency, Lead Time for Changes, Change Failure Rate, Failed Deployment Recovery Time (MTTR), and Reliability. Reliability, once considered one of the other DORA metrics, has now become a core metric, added by Google and many practitioners to explicitly capture uptime and SLO adherence. This addition recognizes that you can deploy frequently with low lead time while still having a service that’s constantly degraded—a gap the original four metrics don’t fully address.
Reliability in practical terms measures the percentage of time a service meets its agreed SLOs for availability and performance. For example, a team might target 99.9% availability over 30 days, meaning less than 43 minutes of downtime. Or they might define reliability as maintaining p95 latency under 200ms for 99.95% of requests.
This metric blends SRE concepts—SLIs, SLOs, and error budgets—with classic DORA velocity metrics. It prevents a scenario where teams optimize for deployment frequency lead time while allowing reliability to degrade. The balance matters: shipping fast is only valuable if what you ship actually works for users.
Typical inputs for Reliability include uptime data from monitoring tools, latency SLIs from APM platforms, error rates from logging systems, and customer-facing incident reports. Organizations serious about this metric usually have Prometheus, Datadog, New Relic, or similar observability platforms already collecting the raw data.
DORA research defines four performance bands—Low, Medium, High, and Elite—based on the combination of all core metrics rather than any single measurement. This holistic view matters because optimizing one metric in isolation often degrades others. True elite performance means excelling across the board.
Elite teams deploy on-demand (often multiple times daily), achieve lead times under one hour, maintain change failure rates below 15%, and restore service within an hour of detection. Low performers struggle at every stage: monthly or less frequent deployments, lead times stretching to months, failure rates exceeding 45%, and recovery times measured in days or weeks. The gap between these tiers isn’t incremental—it’s transformational.
These industry benchmarks are directional guides, not mandates. A team handling medical device software or financial transactions will naturally prioritize stability over raw deployment frequency. A team shipping a consumer mobile app might push velocity harder. Context matters. What DORA research provides is a framework for understanding where you stand relative to organizational performance metrics, such as cycle time, across industries and what improvement looks like.
The most useful benchmarking happens per service or team, not aggregated across your entire engineering organization. A company with one elite-performing team and five low-performing teams will look “medium” in aggregate—hiding both the success worth replicating and the struggles worth addressing. Granular visibility creates actionable insights.
Consider two teams within the same organization. Your payments team, handling PCI-compliant transaction processing, deploys weekly with extensive review gates and achieves 3% CFR with 45-minute MTTR. Your web front-end team ships UI updates six times daily with 12% CFR and 20-minute MTTR. Both might be performing optimally for their context—the aggregate view would tell you neither story.
Typo provides historical trend views plus internal benchmarking, comparing a team to its own performance over the last three to six months. This approach focuses on continuous improvement rather than arbitrary competition with other teams or industry averages that may not reflect your constraints.
The fundamental challenge with DORA metrics isn’t understanding what to measure—it’s that the required data lives scattered across multiple systems. Your production deployments happen in Kubernetes or AWS. Your code changes flow through GitHub or GitLab. Your incidents get tracked in PagerDuty or Opsgenie. Bringing these together requires deliberate data collection and transformation. Most organizations integrate tools like Jira, GitHub, and CI/CD logs to automate DORA data collection, avoiding manual reporting errors.
The main data sources involved include metrics related to development and deployment efficiency, such as DORA metrics and how Typo uses them to boost DevOps performance:
The core approach—pioneered by Google’s Four Keys project—involves extracting events from each system, transforming them into standardized entities (changes, deployments, incidents), and joining them on shared identifiers like commit SHAs or timestamps. A GitHub commit with SHA abc123 becomes a Kubernetes deployment tagged with the same SHA, which then links to a PagerDuty incident mentioning that deployment. To measure DORA metrics effectively, organizations should use automated, continuous tracking through integrated DevOps tools and follow best practices for analyzing trends over time.
Several pitfalls derail DIY implementations. Inconsistent definitions of what counts as a “deployment” across teams. Missing deployment IDs in incident tickets because engineers forgot to add them. Confusion between staging and production environments inflating deployment counts. Monorepo complexity where a single commit might deploy to five different services. Each requires careful handling. Engaging the members responsible for specific areas is critical to getting buy-in and cooperation when implementing DORA metrics.
Here’s a concrete example of the data flow: a developer merges PR #1847 in GitHub at 14:00 UTC. GitHub Actions builds and pushes a container tagged with the commit SHA. ArgoCD deploys that container to production at 14:12 UTC. At 14:45 UTC, PagerDuty fires an alert for elevated error rates. The incident is linked to the deployment, and resolution comes at 15:08 UTC. From this chain, you can calculate: 12 minutes lead time (merge to deploy), one deployment event, one failure (CFR = 100% for this deployment), and 23 minutes MTTR.
Typo replaces custom ETL with automatic connectors that handle this complexity. You connect your Git provider, CI/CD system, and incident tools. Typo maps commits to deployments, correlates incidents to changes, and surfaces DORA metrics in ready-to-use dashboards—typically within a few hours of setup rather than weeks of engineering effort.
Before trusting any DORA metrics, your organization must align on foundational definitions. Without this alignment, you’ll collect data that tells misleading stories.
The critical questions to answer:
Different choices swing metrics dramatically. Counting every canary step as a separate deployment might show 20 daily deployments; counting only final production cutovers shows 2. Neither is wrong—but they measure different things.
The practical advice: start with simple, explicit rules and refine them over time. Document your definitions. Apply them consistently. Revisit quarterly as your deployment processes mature. Perfect accuracy on day one isn’t the goal—consistent, improving measurement is.
Typo makes these definitions configurable per organization or even per service while keeping historical data auditable. When you change a definition, you can see both the old and new calculations to understand the impact.
DORA metrics are designed for team-level learning and process improvement, not for ranking individual engineers or creating performance pressure. The distinction matters more than anything else in this guide. Get the culture wrong, and the metrics become toxic—no matter how accurate your data collection is.
Misusing metrics leads to predictable dysfunction. Tie bonuses to deployment frequency, and teams will split deployments artificially, pushing empty changes to hit targets. Rank engineers by lead time, and you’ll see rushed code reviews and skipped testing. Display Change Failure Rate on a public leaderboard, and teams will stop deploying anything risky—including necessary improvements. Trust erodes. Gaming escalates. Value stream management becomes theater.
The right approach treats DORA as a tool for retrospectives and quarterly planning. Identify a bottleneck—say, high lead time. Form a hypothesis—maybe PRs wait too long for review. Run an experiment—implement a “review within 24 hours” policy and add automated review assignment. Watch the metrics over weeks, not days. Discuss what changed in your next retrospective. Iterate.
Here’s a concrete example: a team notices their lead time averaging 4.2 days. Digging into the data, they see that 3.1 days occur between PR creation and merge—code waits for review. They pilot several changes: smaller PR sizes, automated reviewer assignment, and a team norm that reviews take priority over new feature work. After six weeks, lead time drops to 1.8 days. CFR holds steady. The experiment worked.
Typo supports this culture with trend charts and filters by branch, service, or team. Engineering leaders can ask “what changed when we introduced this process?” and see the answer in data rather than anecdote. Blameless postmortems become richer when you can trace incidents back to specific patterns.
Several anti-patterns consistently undermine DORA metric programs:
Consider a cautionary example: a team proudly reports MTTR dropped from 3 hours to 40 minutes. Investigation reveals they achieved this by raising alert thresholds so fewer incidents get created in the first place. Production failures still happen—they’re just invisible now. Customer complaints eventually surface the problem, but trust in the metrics is already damaged.
The antidote is pairing DORA with qualitative signals. Developer experience surveys reveal whether speed improvements come with burnout. Incident reviews uncover whether “fast” recovery actually fixed root causes. Customer feedback shows whether delivery performance translates to product value.
Typo combines DORA metrics with DevEx surveys and workflow analytics, helping you spot when improvements in speed coincide with rising incident stress or declining satisfaction. The complete picture prevents metric myopia.
Since around 2022, widespread adoption of AI pair-programming tools has fundamentally changed the volume and shape of code changes flowing through engineering organizations. GitHub Copilot, Amazon CodeWhisperer, and various internal LLM-powered assistants accelerate initial implementation—but their impact on DORA metrics is more nuanced than “everything gets faster.”
AI often increases throughput: more code, more PRs, more features started. But it can also increase batch size and complexity when developers accept large AI-generated blocks without breaking them into smaller, reviewable chunks. This pattern may negatively affect Change Failure Rate and MTTR if the code isn’t well understood by the team maintaining it.
Real patterns emerging across devops teams include faster initial implementation but more rework cycles, security concerns from AI-suggested code that doesn’t follow organizational patterns, and performance regressions surfacing in production because generated code wasn’t optimized for the specific context. The AI helps you write code faster—but the code still needs human judgment about whether it’s the right code.
Consider a hypothetical but realistic scenario: after enabling AI assistance organization-wide, a team sees deployment frequency, lead time, and CFR change—deployment frequency increase 20% as developers ship more features. But CFR rises from 10% to 22% over the same period. More deployments, more failures. Lead time looks better because initial coding is faster—but total cycle time including rework is unchanged. The AI created velocity that didn’t translate to actual current performance improvement.
The recommendation is combining DORA metrics with AI-specific visibility: tracking the percentage of AI-generated lines, measuring review time for AI-authored PRs versus human-authored ones, and monitoring defect density on AI-heavy changes. This segmentation reveals where AI genuinely helps versus where it creates hidden costs.
Typo includes AI impact measurement that tracks how AI-assisted commits correlate with lead time, CFR, and MTTR. Engineering leaders can see concrete data on whether AI tools are improving or degrading outcomes—and make informed decisions about where to expand or constrain AI usage.
Maintaining trustworthy DORA metrics while leveraging AI assistance requires intentional practices:
AI can also help reduce Lead Time and accelerate incident triage without sacrificing CFR or MTTR. LLMs summarizing logs during incidents, suggesting related past incidents, or drafting initial postmortems speed up the human work without replacing human judgment.
The strategic approach treats DORA metrics as a feedback loop on AI rollout experiments. Pilot AI assistance in one service, monitor metrics for four to eight weeks, compare against baseline, then expand or adjust based on data rather than intuition.
Typo can segment DORA metrics by “AI-heavy” versus “non-AI” changes, exposing exactly where AI improves or degrades outcomes. A team might discover that AI-assisted frontend changes show lower CFR than average, while AI-assisted backend changes show higher—actionable insight that generic adoption metrics would miss.
DORA metrics provide a powerful foundation, but they don’t tell the whole story. They answer “how fast and stable do we ship?” They don’t answer “are we building the right things?” or “how healthy are our teams?” Tracking other DORA metrics, such as reliability, can provide a more comprehensive view of DevOps performance and system quality. A complete engineering analytics practice requires additional dimensions.
Complementary measurement areas include:
Frameworks like SPACE (Satisfaction, Performance, Activity, Communication, Efficiency) complement DORA by adding the human dimension. Internal DevEx surveys help you understand why metrics are moving, not just that they moved. A team might show excellent DORA metrics while burning out—something the numbers alone won’t reveal.
The practical path forward: start small. DORA metrics plus cycle time analysis plus a quarterly DevEx survey gives you substantial visibility without overwhelming teams with measurement overhead. Evolve toward a multi-dimensional engineering scorecard over six to twelve months as you learn what insights drive action.
Typo unifies DORA metrics with delivery signals (cycle time, review time), quality indicators (churn, defect rates), and DevEx insights (survey results, burnout signals) in one platform. Instead of stitching together dashboards from five different tools, engineering leaders get a coherent view of how the organization delivers software—and how that delivery affects the people doing the work.
The path from “we should track DORA metrics” to actually having trustworthy data is shorter than most teams expect. Here’s the concrete approach:
Most engineering organizations can get an initial, automated DORA view in Typo within a day—without building custom pipelines, writing SQL against BigQuery, or maintaining ETL scripts. The platform handles the complexity of correlating events across multiple systems.
For your first improvement cycle, pick one focus metric for the next four to six weeks. If lead time looks high, concentrate there. If CFR is concerning, prioritize code quality and testing investments. Track the other metrics to ensure focused improvement efforts don’t create regressions elsewhere.
Ready to see where your teams stand? Start a free trial to connect your tools and get automated DORA metrics within hours. Prefer a guided walkthrough? Book a demo with our team to discuss your specific context and benchmarking goals.
DORA metrics are proven indicators of engineering effectiveness—backed by a decade of research and assessment DORA work across tens of thousands of organizations. But their real value emerges when combined with contextual analytics, AI impact measurement, and a culture that uses data for learning rather than judgment. That’s exactly what Typo is built to provide: the visibility engineering leaders need to help their teams deliver software faster, safer, and more sustainably.
DORA metrics provide DevOps teams with a clear, data-driven framework for measuring and improving software delivery performance. By implementing DORA metrics, teams gain visibility into critical aspects of their software delivery process, such as deployment frequency, lead time for changes, time to restore service, and change failure rate. This visibility empowers teams to make informed decisions, prioritize improvement efforts, and drive continuous improvement across their workflows.
One of the most significant benefits is the ability to identify and address bottlenecks in the delivery pipeline. By tracking deployment frequency and lead time, teams can spot slowdowns and inefficiencies, then take targeted action to streamline their processes. Monitoring change failure rate and time to restore service helps teams improve production stability and reduce the impact of incidents, leading to more reliable software delivery.
Implementing DORA metrics also fosters a culture of accountability and learning. Teams can set measurable goals, track progress over time, and celebrate improvements in delivery performance. As deployment frequency increases and lead time decreases, organizations see faster time-to-market and greater agility. At the same time, reducing failure rates and restoring service quickly enhances customer trust and satisfaction.
Ultimately, DORA metrics provide DevOps teams with the insights needed to optimize their software delivery process, improve organizational performance, and deliver better outcomes for both the business and its customers.
Achieving continuous improvement in software delivery requires a deliberate, data-driven approach. DevOps teams should focus on optimizing deployment processes, reducing lead time, and strengthening quality assurance to deliver software faster and more reliably.
Start by implementing automated testing throughout the development lifecycle. Automated tests catch issues early, reduce manual effort, and support frequent, low-risk deployment events.
Streamlining deployment processes—such as adopting continuous integration and continuous deployment (CI/CD) pipelines—helps minimize delays and ensures that code moves smoothly from development to the production environment.
Regularly review DORA metrics to identify bottlenecks and areas for improvement. Analyzing trends in lead time, deployment frequency, and change failure rate enables teams to pinpoint where work is getting stuck or where quality issues arise. Use this data to inform targeted improvement efforts, such as refining code review practices, optimizing test suites, or automating repetitive tasks.
Benchmark your team’s performance against industry standards to understand where you stand and uncover opportunities for growth. Comparing your DORA metrics to those of high performing teams can inspire new strategies and highlight areas where your processes can evolve.
By following these best practices—embracing automation, monitoring key metrics, and learning from both internal data and industry benchmarks—DevOps teams can drive continuous improvement, deliver higher quality software, and achieve greater business success.
DevOps research often uncovers several challenges that can hinder efforts to measure and improve software delivery performance. One of the most persistent obstacles is collecting accurate data from multiple systems. With deployment events, code changes, and incidents tracked across different tools, consolidating this information for key metrics like deployment frequency and lead time can be time-consuming and complex.
Defining and measuring these key metrics consistently is another common pitfall. Teams may interpret what constitutes a deployment or a failure differently, leading to inconsistent data and unreliable insights. Without clear definitions, it becomes difficult to compare performance across teams or track progress over time.
Resistance to change can also slow improvement efforts. Teams may be hesitant to adopt new measurement practices or may struggle to prioritize initiatives that align with organizational goals. This can result in stalled progress and missed opportunities to enhance delivery performance.
To overcome these challenges, focus on building a culture of continuous improvement. Encourage open communication about process changes and the value of data-driven decision-making. Leverage automation and integrated tools to streamline data collection and analysis, reducing manual effort and improving accuracy. Prioritize improvement efforts that have the greatest impact on software delivery performance, and ensure alignment with broader business objectives.
By addressing these common pitfalls, DevOps teams can more effectively measure performance, drive meaningful improvement, and achieve better outcomes in their software delivery journey.
For DevOps teams aiming to deepen their understanding of DORA metrics and elevate their software delivery performance, a wealth of resources is available. The Google Cloud DevOps Research and Assessment (DORA) report is a foundational resource, offering in-depth analysis of industry trends, best practices, and benchmarks for software delivery. This research provides valuable context for teams looking to compare their delivery performance against industry standards and identify areas for continuous improvement.
Online communities and forums, such as the DORA community, offer opportunities to connect with other teams, share experiences, and learn from real-world case studies. Engaging with these communities can spark new ideas and provide support as teams navigate their own improvement efforts.
In addition to research and community support, a range of tools and platforms can help automate and enhance the measurement of software delivery performance. Solutions like Vercel Security Checkpoint provide automated security validation for deployments, while platforms such as Typo streamline the process of tracking and analyzing DORA metrics across multiple systems.
By leveraging these resources—industry research, peer communities, and modern tooling—DevOps teams can stay current with the latest developments in software delivery, learn from other teams, and drive continuous improvement within their own organizations.



Implement engineering metrics, gather SDLC insights & set continuous improvement goals in your dev teams.
Try Live Demo
We're on a mission to build engaged, productive tech teams. Try it out for free!


Follow us on:




